
-
描述秋天美景的诗句
https://baijiahao.baidu.com/s?id=1776646546359667213&wfr=spider&for=pc -
LLM长上下文外推方法
现在的LLM都集中在卷上下文长度了,最新的Claude3已经支持200K的上下文,见:cost-context。下面是一些提升LLM长度外推能力的方法总结:
-
YOLO v1讲解
YOLO是最经典的一阶目标检测框架,记录一下v1思路。
-
ViT的若干细节
之前只看了ViT的大概结构,具体的模型细节和代码实现知之甚少。随着ViT逐渐成为CV领域的backbone,有必要重新审视下。
-
keep主题从3.x升级到4.x后GitHub Actions自动部署后文章更新时间异常的问题
keep主题4.x新增了很多功能配置,在升级的过程中遇到了一些问题,在此记录一下:
-
CUDA编程模型
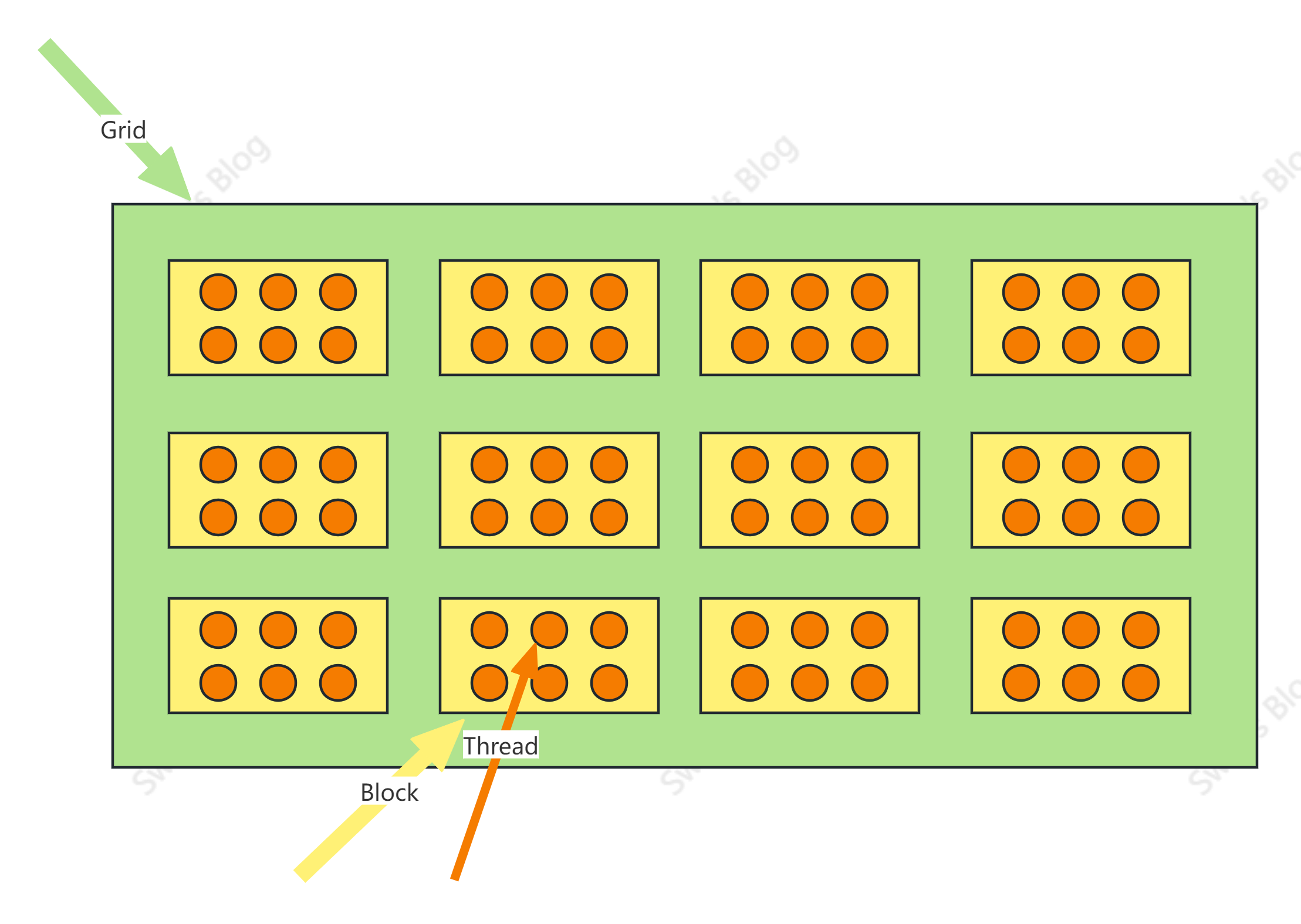
参照数学坐标系,grid的规格是 $(4,3)$ ,block的规格是 $(3,2)$
-
MIND解读
这篇paper的核心是胶囊网络,该网络采用了动态路由算法自动对用户历史行为序列进行聚类,提取出多个兴趣向量,代表用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化。
-
TDM检索技术讲解
召回的任务是从海量商品库中挑选出与用户最相关的topK个商品。传统的召回检索时间复杂度是 $O(N)$ ,而阿里的TDM通过对全库商品构建一个树索引,将时间复杂度降低到 $O(logN)$ 。
-
新一代粗排系统COLD
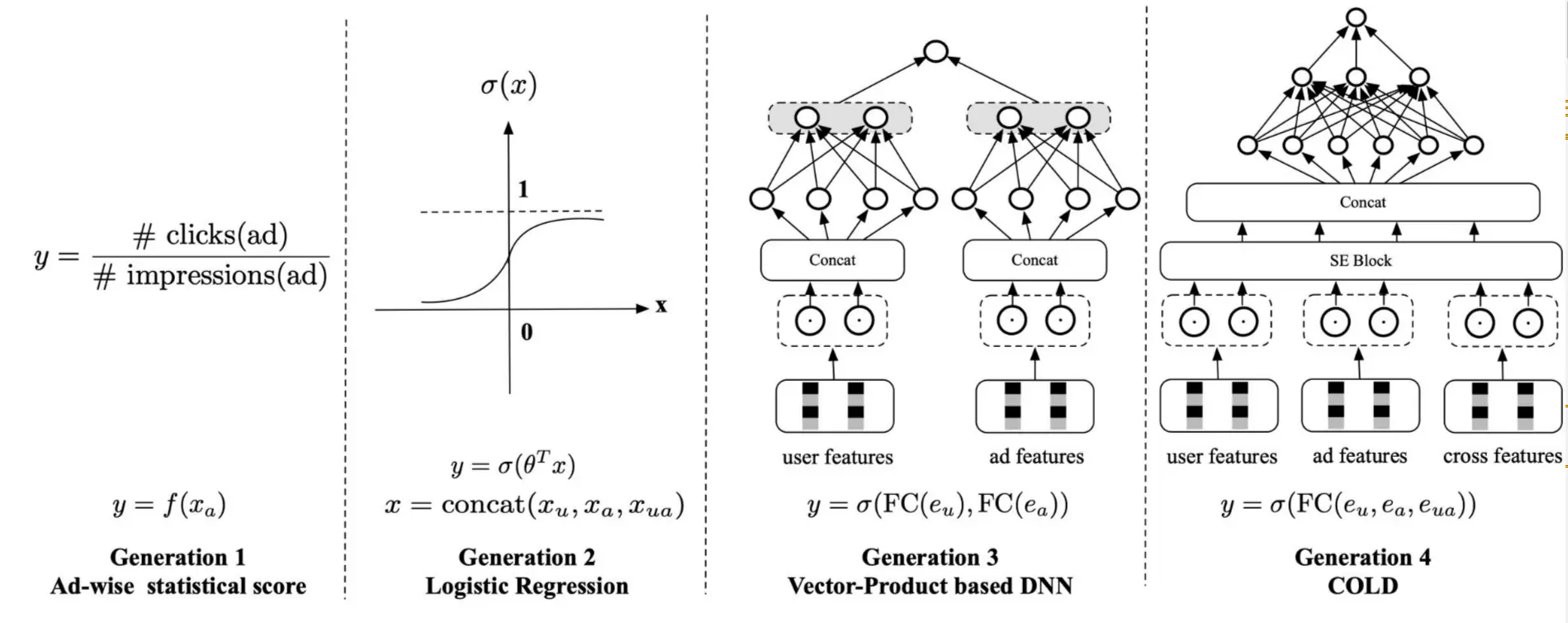
为了让粗排支持交叉特征来提升模型性能,同时又为了降低引入交叉特征、复杂模型所带来的预估延迟和资源消耗,阿里团队提出了COLD,在模型效果和算力间取得了平衡。
-
Flash-Attention
这是一篇硬核的优化Transformer的工作。众所周知,Transformer模型的计算量和储存复杂度是 $O(N^2)$ 。尽管先前有了大量的优化工作,比如LongFormer、Sparse Transformer、Reformer等等,一定程度上减轻了Transformer的资源消耗,但对Transformer的性能有所折损,且扩展性不强,不能泛化到其它领域、以及复杂结构的叠加。