LLM在SFT之后会产生大量的冗余参数(delta参数),阿里团队提出DARE方法来消除delta参数,并将其合并到PRE模型中,从而实现多源模型能力的吸收。
DARE无需GPU重新训练,其思路非常简单,就跟dropout类似:
两个步骤:
- drop:随机mask参数为0
- rescale:对保存的参数rescale,这样可以保证神经元期望值不变:$E_{not_{mask}}=x,E_{mask}=\frac{p*x}{p}$
传统的模型融合只是对神经元进行加权求和,这样会导致模型能力骤降。DARE方法通过dropout避免了这种问题。
多源模型融合
流程图:
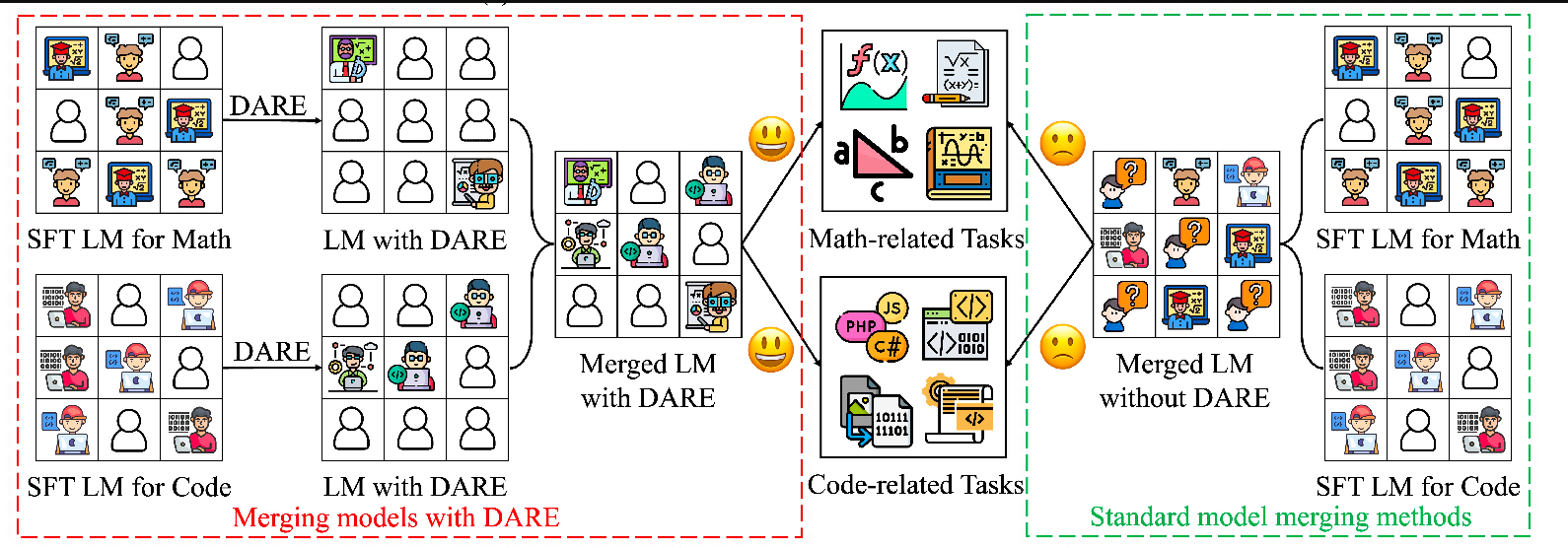
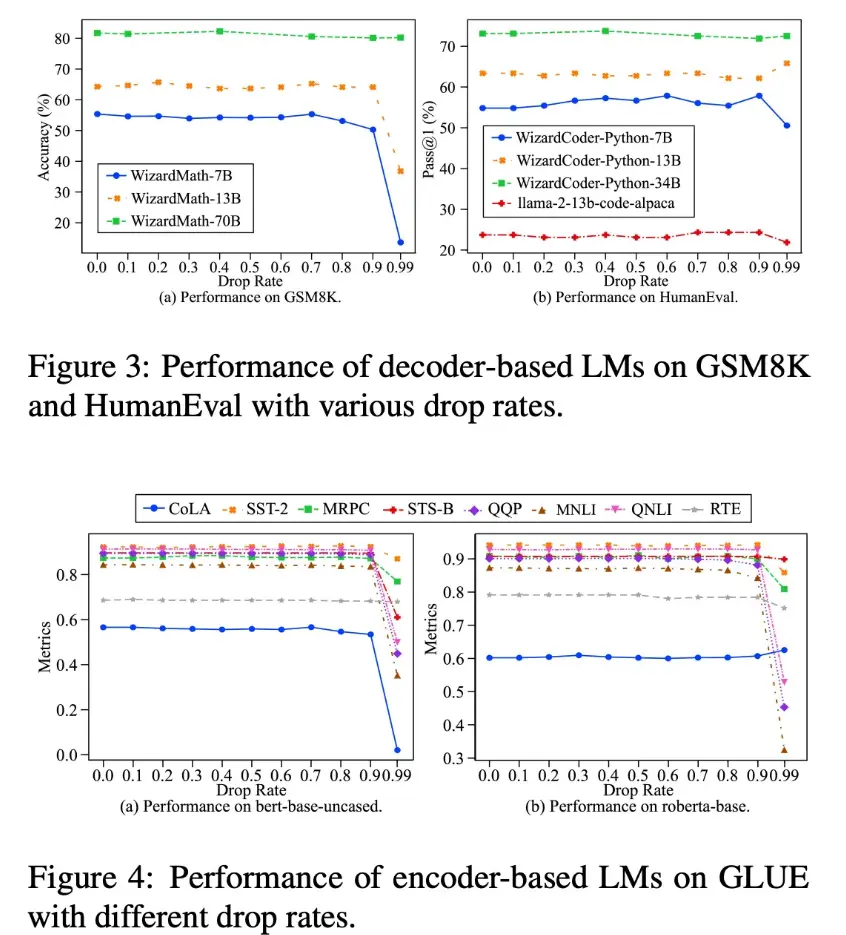
实验结果
参考
