LLM长上下文外推方法

现在的LLM都集中在卷上下文长度了,最新的Claude3已经支持200K的上下文,见:cost-context。下面是一些提升LLM长度外推能力的方法总结:
数据工程
符尧大佬的最新工作:Data Engineering for Scaling Language Models to 128K Context
作者假设LLM在预训练中已经获得了128k上下文内处理任意输入位置信息能力。现在这种能力只需通过轻量级的持续预训练与适当的数据混合轻松地激发出来:
- 在更长的数据上继续预训练
- 混合各领域的数据
- 长序列上采样
网络结构
陈丹琦团队最新工作:
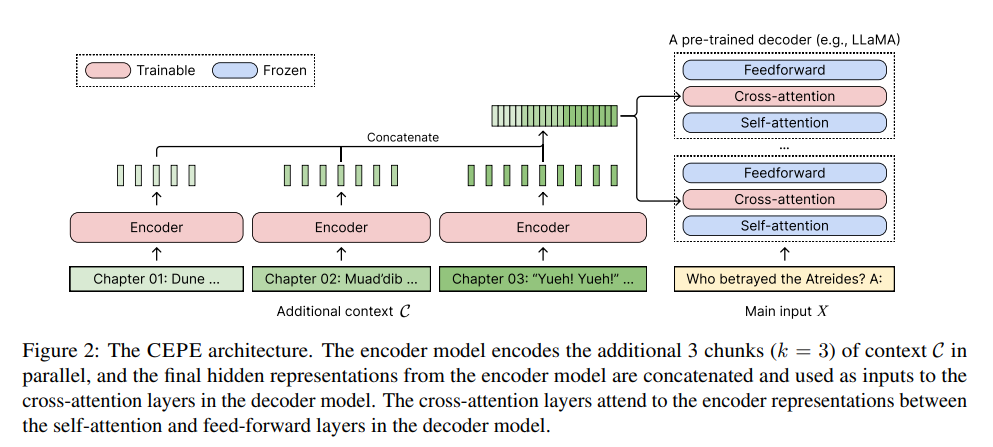
- 小型编码器:并行对长上下文进行分块编码
- 交叉注意力模块:插入到解码器的每一层,用于关注编码器表示
位置编码
RoPE
最经典的一版,具体讲解见:旋转位置编码
Position Interpolation
在两个token的距离相差超过2k时,RoPE远程衰减特性将不稳定。线性插值通过在两个位置之间再插入位置,进行区间细分,然后在少量样本上继续预训练,即可外推到32k等
NTK-Aware Interpolation
主要思路:高频外推,低频内插。
NTK的优点是不用微调的情况下,能比线性插值做得好。但是由于低频部分还是会有部分被外推到超出范围的值,因此在设定系数的时候,要比需要的设得更大才行。
其他方法
从attention score层面缓解:
- YaRN
- logn
小结
较短的预训练模型(2k、4k)应用在长上下文会因为训练和推理的两个不一致导致效果下降:
- 推理时用到了没训练过的位置编码
- 推理时注意力机制所处理的token数量远超训练时的数量,导致注意力机制的崩坏
这两个问题分别可以从位置编码和attention score的放缩来缓解:
- 线性插值PI、NTK插值、分部NTK插值都可以缓解第一个问题,
- logn和YaRN则把第二个问题纳入的考虑。目前这些方法在实际应用中也有很多变体,包括超参的修改,函数的重定义等