YOLO v1讲解

YOLO是最经典的一阶目标检测框架,记录一下v1思路。
整体流程
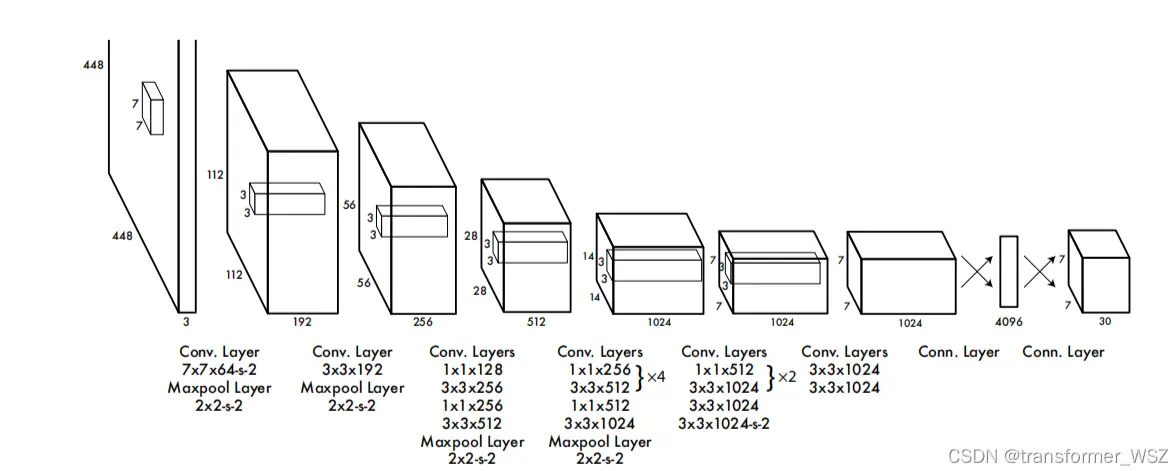
- 输入数据一张 $448 \times 448 \times 3$ 的图片,切分成 $7 \times 7$ 的网格
- 将图片经过多层CNN,下采样得到 $7 \times 7 \times 30$ 的feature map,其中 $30 = 2 * (4 + 1) + 20$
- $2$ 表示每个单元格预测两个边界框
- $4 + 1$ 分别表示边界框的位置以及边界框的置信度(一是该边界框含有目标的可能性大小,0或者1;二是这个边界框的准确度,用IOU衡量)
- $20$ 表示最置信的边界框预测该框属于哪个类别的概率。无论单元格预测多少个边界框,都是只取一个边界框来预测类别,即默认每个单元格只有一个物体,这也是v1的缺陷
- 计算loss,开始训练
总结一下,将图片分割成 $S \times S$ 个单元格,每个单元格预测出 $S \times S \times ( B * 5 + C )$ 大小的张量。对应上述流程:$S = 7, B = 2, C = 20$
损失函数
- 第一项是边界框中心坐标的误差
- 第二项是边界框的高与宽的误差
- 第三项是包含目标的边界框的置信度误差(在训练过程中,如果该边界框包含目标,则置信度取IOU,而不是1,对应下面的代码可以理解)
- 第四项是不包含目标的边界框的置信度误差
- 第五项是包含目标的单元格的分类误差
值得注意的是,在推理过程中,我们是不可能计算出跟gt的IOU,所以取最置信的边界框作为predict label。