
之前只看了ViT的大概结构,具体的模型细节和代码实现知之甚少。随着ViT逐渐成为CV领域的backbone,有必要重新审视下。
patch -> token
为了将图片处理成序列格式,很自然地想到将图片分割成一个个patch,再把patch处理成token。
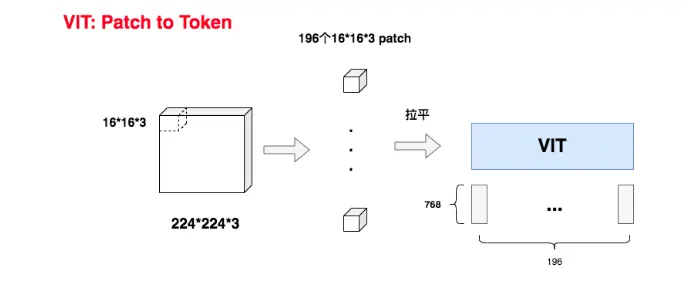
假设图片大小为 $224 \times 224 \times 3$ (即 $H \times W \times C$ ),每个patch大小为 $16 \times 16 \times 3$,那么序列长度就是 $196$,序列的形状是 $196 \times 768$。
如何将大小为 $16 \times 16 \times 3$ 的patch,映射为 $768$ 维的token?源码是直接将其reshape
在reshape之后,还需要过一层$768 \times 768$的embedding层。因为reshape后的$768$维向量是参数无关的,不参与梯度更新,过完embedding层,即拥有了token embedding的语义信息。
处理成patch的好处
- 减少计算量:如果按照pixel维度计算self-attention,那复杂度大大增加。patch size越大,复杂度越低。stable diffusion也是这个思路,在latent space进行扩散,而不是pixel
- 减少图像冗余信息:图像是有大量冗余信息的,处理成patch不影响图片语义信息
position embedding
论文采用的是可学习式位置编码,跟bert类似,初始化一个可学习的1-d参数向量
其它的位置编码方案结果对比: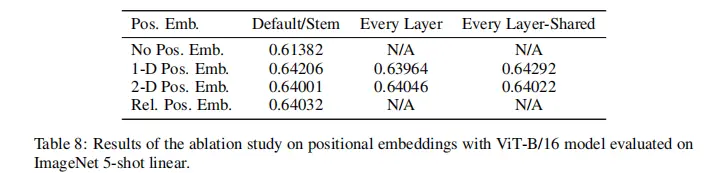
个人感觉2-d位置编码更make sense,它保留了patch之间的空间位置关系,跟CNN类似。直接粗暴地拉平成一维序列,则丢弃了这种空间信息。
实验结果
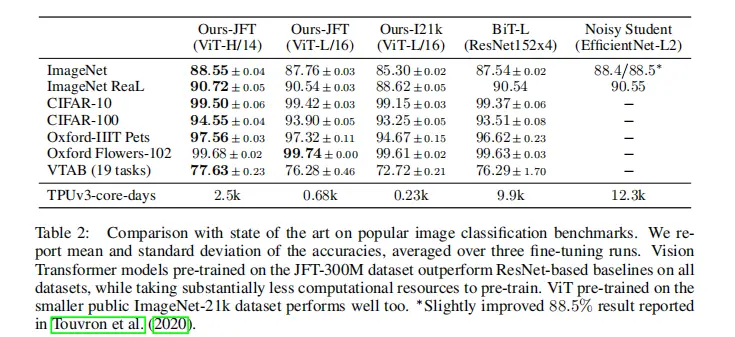
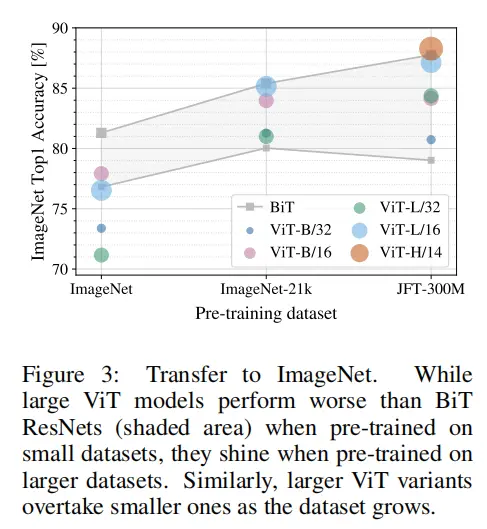
在相同的数据集JFT-300M上预训练后,ViT在所有的下游任务上,都超过了BiT。值得注意的是,准确率上提升不大,但训练时间大为缩短。
可能是基于Transformer架构的VIT,和卷积神经网络相比,更适合做切分均匀的矩阵计算,这样我们就能把参数均匀切到不同卡上做分布式训练,更好利用GPU算力,提升训练效率。
但transformer架构有个独门绝技,那就是大力出奇迹。数据量越大,模型参数越多,任务效果就越好。下图就是证明:
ViT学习到空间局部性了吗?
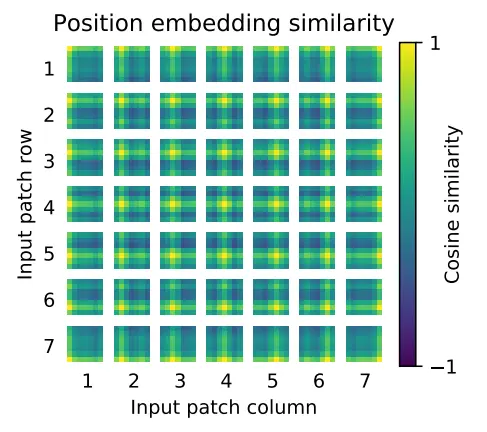
可以看到,每个patch除了跟自己最相似外,其与周围的patch相关性高于距离较远的patch。这就说明ViT通过位置编码,已经学到了一定的空间局部性。
总结
- ViT证明了Transformer架构在CV领域的可行性,以后Transformer将大一统各领域。NLP的成功经验非常有潜力迁移到CV领域,比如scaling law,大数据+大模型的范式将开拓出CV的新一片天地。
- 大数据+大模型真的是既无脑又有效,通过这种方式让Transformer自己去学习到特定领域的归纳偏置。可以说Transformer下限比CNN低,但上限又是CNN无法企及的。