Multi Query Attention & Group Query Attention

Multi Query Attention(MQA)在2019年就被提出来了,用于推理加速,但在当时并没有受到很多关注,毕竟一张2080就能跑Bert-base了。随着LLM的大火,MQA所带来的收益得以放大。
思路
Multi Query Attention(MQA)跟Multi Head Attention(MHA)只有一词之差,但其思路非常简单,几乎跟MHA一致:

MHA的Query、Key、Value分拆成8个头,每个头进行self-attention运算,而MQA是Query分成8个头,每个头共享一组Key和Value
1 | MHA: Q, K, V = (512, 768), # seq_len, hidden_dim |
代码实现
MHA
1
2
3
4
5
6
7...
self.Wqkv = nn.Linear(
d_model,
d_model * 3,
device=device,
)
...将
d_model * 3拆成3个768维MQA
1
2
3
4
5
6
7...
self.Wqkv = nn.Linear(
d_model,
d_model + 2 * self.head_dim,
device=device,
)
...将
d_model + 2 * self.head_dim拆成1个768维 + 2个96维
可以看到参数数量大幅减少。
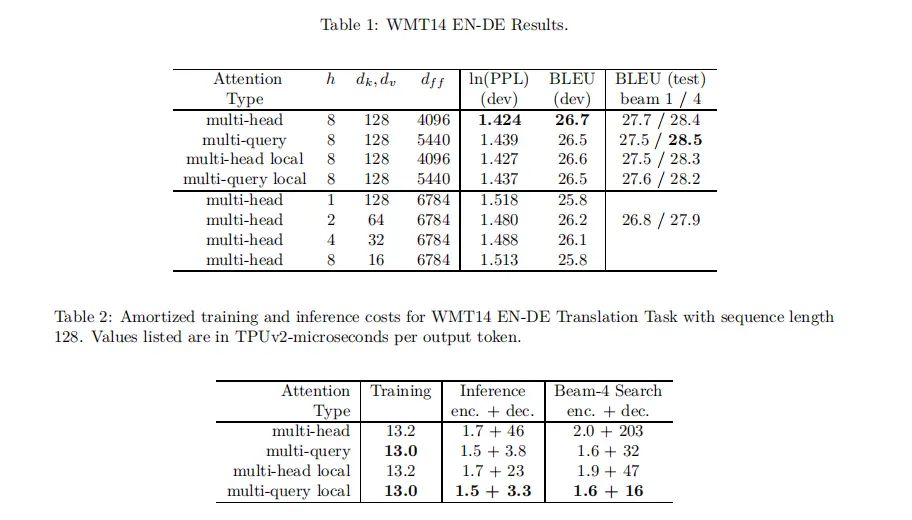
实验结果
实验指标略微降低,但推理加速非常明显。
Group Query Attention
Q拆分成8个头,K和V分别拆成4个头,然后对应进行attention运算。