BERT面试要点

BERT的模型结构如下图所示:
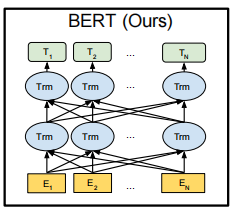
1. 两个预训练任务
Task1:Masked Language Model
MLM是指在训练的时候随机从输入语料上mask掉一些单词,然后通过上下文来预测该单词。在BERT的实验中,15%的Token会被随机Mask掉。这其中的80%会直接替换为[Mask],10%的时候将其替换为其它任意单词,10%的时候会保留原始Token。
这么做的原因:如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ‘hairy’。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
Task2:Next Sentence Prediction
NSP的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext’,否则输出’NotNext’。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从语料中提取的,它们的关系是NotNext的。这个关系保存在[CLS]符号中。
2. BERT的输入与输出
输入:
- Token Embeddings: 通过查询词表将文本中的每个字转换为一维向量;
- Segmentation Embeddings: 对应BERT里面的下一句的预测任务,所以会有两句拼接起来,上句与下句,上句有上句段向量,下句则有下句段向量,也就是图中A与B;
- Postion Embeddings: 由于self-attention不能记住文本的时序信息,所以需要加入位置编码。BERT通过初始化参数矩阵来学习位置信息。
输出:
- 输入各字对应的融合全文语义信息后的向量表示
- CLS: 编码了整个句子语义的特征向量
3. BERT的局限性
- BERT 在第一个预训练阶段,假设句子中多个单词被 Mask 掉,这些被 Mask 掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。
- BERT 的在预训练时会出现特殊的[MASK],但是它在下游的 fine-tune 中不会出现,这就出现了预训练阶段和 fine-tune 阶段不一致的问题。其实这个问题对最后结果产生多大的影响也是不够明确的,因为后续有许多 BERT 相关的预训练模型仍然保持了[MASK]标记,也取得了很大的结果,而且很多数据集上的结果也比 BERT 要好。但是确确实实引入[MASK]标记,也是为了构造自编码语言模型而采用的一种折中方式。
4. ELMo、OpenAI GPT、BERT区别
- 特征提取器:ELMo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,并且Transformer并行能力强。elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层。
- 单/双向语言模型:GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。
- GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,使用了完整句子。