Transformer面试要点

记录一下常见的Transformer面试要点:
Transformer的核心在如下两张图上:
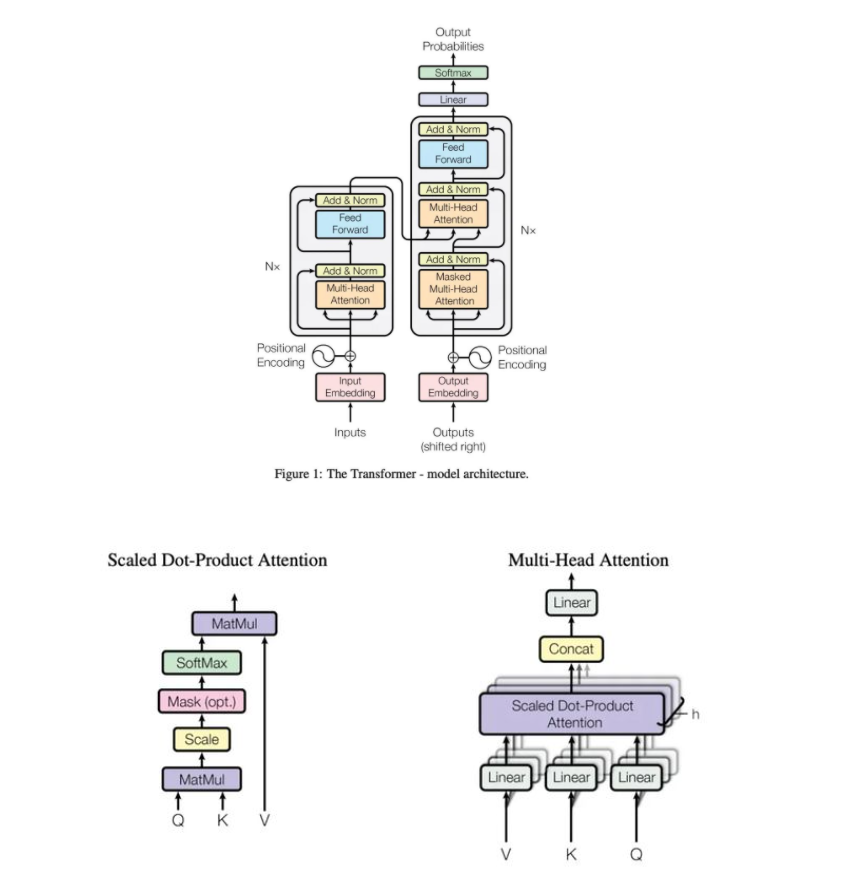
1. 为什么Transformer 需要进行 Multi-head Attention?
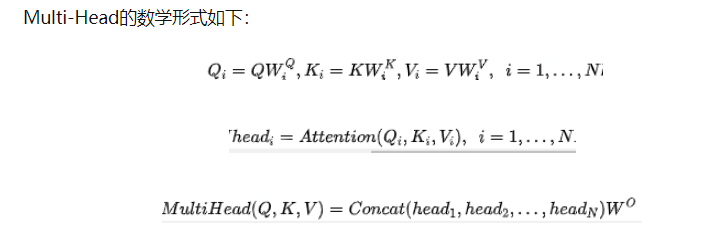
- 将模型分为多个头,形成多个子空间,让模型去关注不同方面的信息;
- 把多头注意力看作一个ensemble,模型内部的集成,类似于CNN中使用的多个卷积核,所以很多时候可以认为多头注意力可以帮助我们捕捉到更为丰富的特征信息。
2. Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
如果Q,K,V都是一个值,那么就变为了Self-Attention的形式:
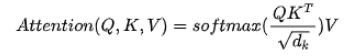
在实践中,Q和K的乘法是为了得到二者的相似度,一般我们的K和V是相同的,Q和K进行操作是为了得到一个attention score矩阵,这样可以得到Q关于V的表示,但一般我们再计算Q,K,V的时候会先都分别乘上一个不同的矩阵W,这么做可以增加模型的表达能力,实践中经常也会带来一定的帮助。
3. Transformer中的attention为什么要进行scaled?
softmax的计算公式如下:
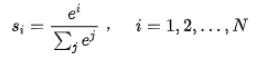
- 非常大的$d_k$值会将softmax推向梯度非常小的区域,梯度消失为0,造成参数更新困难
- $\frac{1}{\sqrt{d_k}}$ 使得$D(\frac{qk}{\sqrt{d_k}})=1$,有效地控制了梯度消失的问题
4. Attention相对于CNN、RNN的优势?
- 参数少,算力要求低
- 并行化,速度快
- 可解释性强,不会遗忘长文本的信息
5. Attention的计算方式
- 多层MLP:$a(q, k)=w_{2}^{T} \tanh \left(W_{1}[q ; k]\right)$
- BiLinear: $a(q, k)=q^{T} W k$
- Scaled-Dot Product: $a(q, k)=\frac{q^{T} k}{\sqrt{d_{k}}}$
- 欧式距离
- cosine
6. 残差网络的作用
ResNet的目标是在网络加深的情况下解决网络退化的问题。
7. LayerNorm的作用,为什么不用BN?
归一化的作用:
- 保持每一层特征分布的稳定性,将梯度从饱和区拉回非饱和区,从而加快模型训练速度,缓解过拟合
LN not BN:
BN对batch_size很敏感,LN不存在这个问题
CV使用BN是认为不同卷积核feature map(channel维)之间的差异性很重要,LN会损失channel的差异性,对于batch内的不同样本,同一卷积核提取特征的目的性是一致的,所以使用BN仅是为了进一步保证同一个卷积核在不同样本上提取特征的稳定性。
而NLP使用LN是认为batch内不同样本同一位置token之间的差异性更重要,而embedding维,网络对于不同token提取的特征目的性是一致的,使用LN是为了进一步保证在不同token上提取的稳定性。NLP每个序列的长度是不一致的,BN不适用。
8. Position Encoding的设计思路
原因:
- 单词在句子中的位置和排列顺序非常重要,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念;
- Transformer使用纯attention结构,丢失了词序信息,有必要把词序信号加到词向量上帮助模型学习这些信息。
线性分配一个数值给每个时间步的缺点?
- 数值巨大,且模型可能遇到比训练集所有句子都要长的句子;
- 数据集中不一定在所有数值上都会包含相对应长度的句子,也就是模型很有可能没有看到过任何一个这样的长度的样本句子,这会严重影响模型的泛化能力;
良好的PE方案需满足以下要求:
- 它能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的;
- 它必须是确定性的。
相对位置的线性关系
正弦曲线函数的位置编码的另一个特点是,它能让模型毫不费力地关注相对位置信息。具体公式推导见More: 相对位置的线性关系