MIND解读

这篇paper的核心是胶囊网络,该网络采用了动态路由算法自动对用户历史行为序列进行聚类,提取出多个兴趣向量,代表用户的不同兴趣。当用户再有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化。
前置知识-胶囊网络
本质上就是个聚类网络,将输入的多个向量聚类输出多个向量:
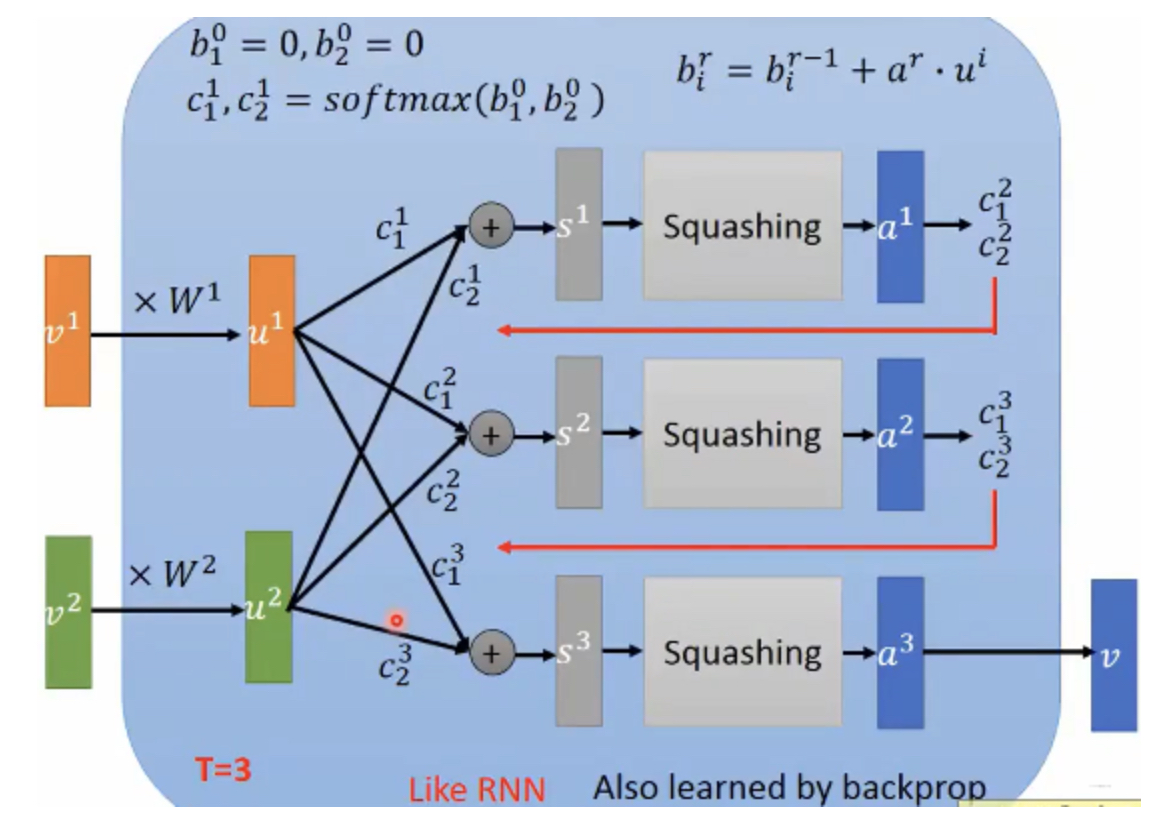
算法迭代流程:
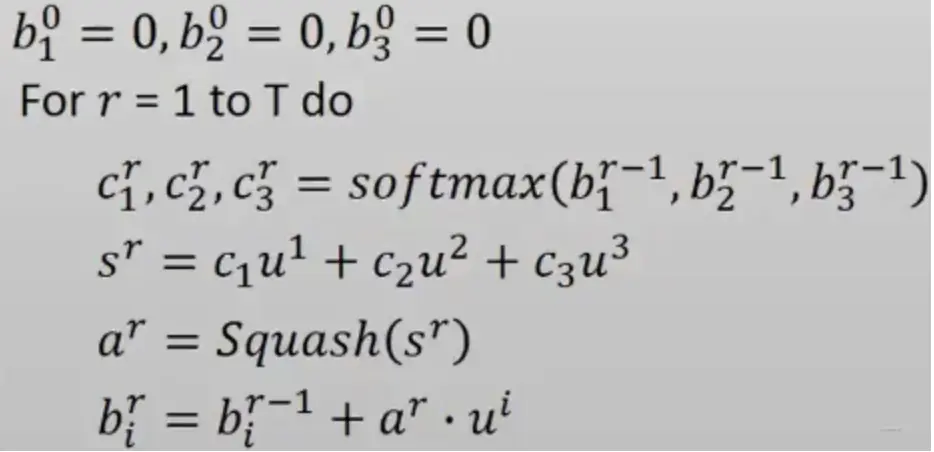
MIND模型
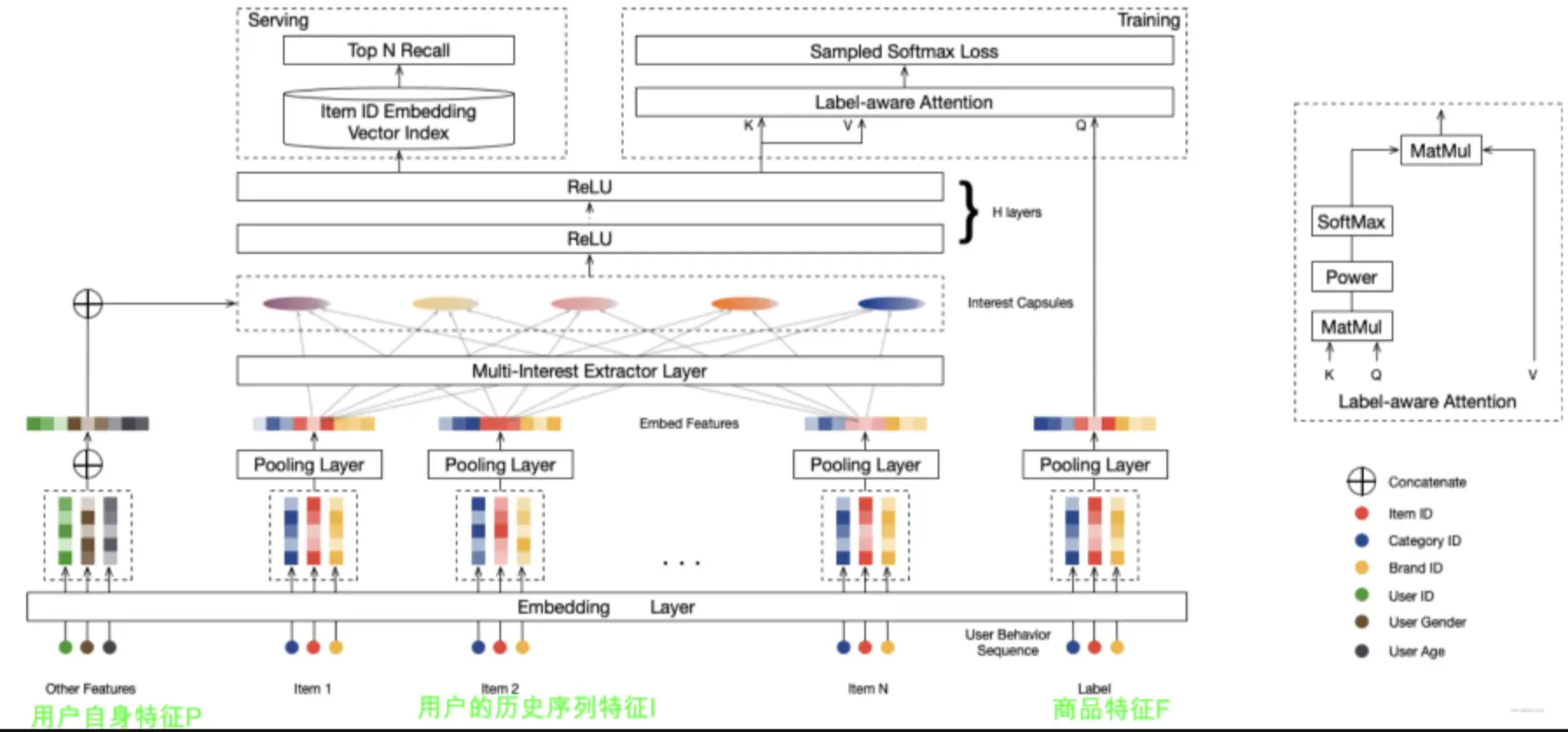
训练
用户向量(item向量对用户多个兴趣向量的weighted sum):
loss:
Then, the overall objective function for training MIND is
由于$\mathcal{D}$数量太大,团队采用了负采样技术
在线服务
同时利用MIND模型产出的多个兴趣向量进行ann检索召回,最终排序得到topK个商品
疑问
- 如何确定兴趣胶囊的数量?
团队用了一种启发式方式自适应调整聚类中心的数量:
该超参对实验影响多大,团队并没有在这上面进行深入实验
- 既然胶囊网络是为了聚类,为什么不直接使用k-means方法?
- 论文说当用户有新的交互时,通过胶囊网络,还能实时的改变用户的兴趣表示向量,做到在召回阶段的实时个性化。但如果是用户兴趣发生变化了呢?比如之前有两个兴趣胶囊(体育、旅游),现在用户多了个兴趣(数码),那就要新增一个兴趣胶囊,等于模型要重新训练?