TDM检索技术讲解

召回的任务是从海量商品库中挑选出与用户最相关的topK个商品。传统的召回检索时间复杂度是 $O(N)$ ,而阿里的TDM通过对全库商品构建一个树索引,将时间复杂度降低到 $O(logN)$ 。
模型概览
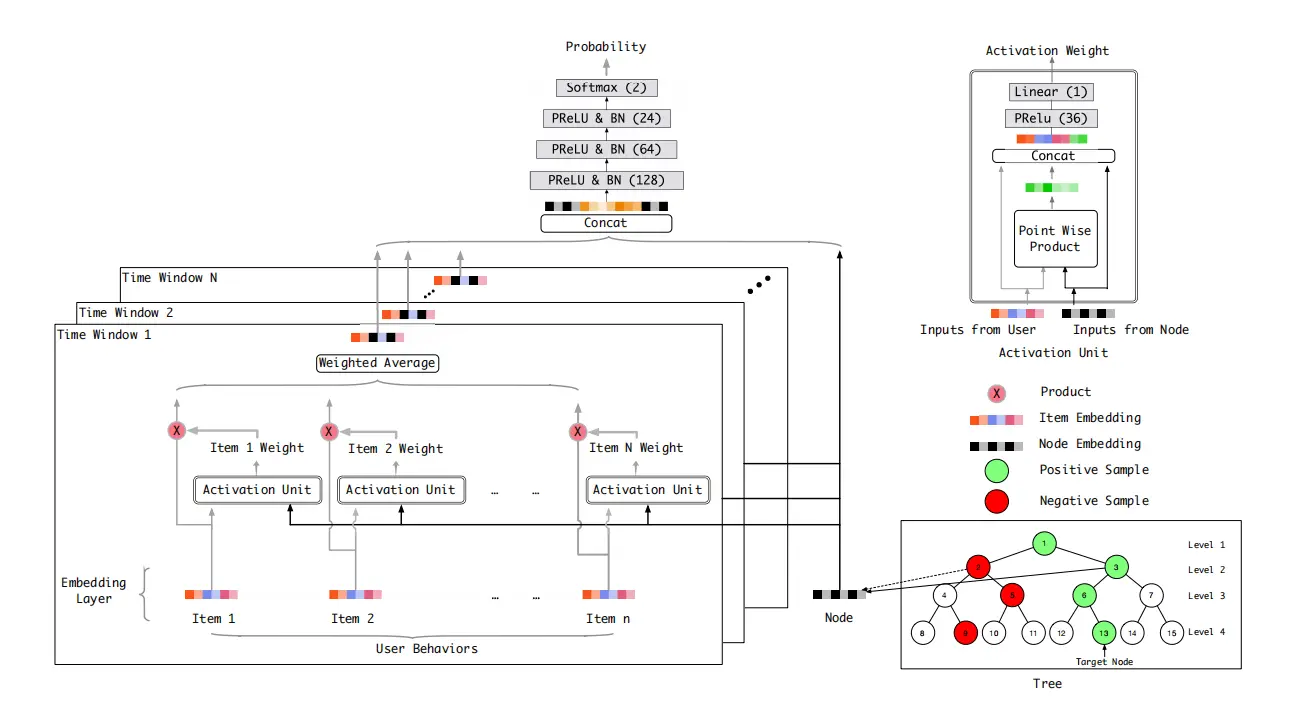
树的每个节点输入到左侧复杂模型的时候,都是一个embedding,这样user向量和item向量可以提早交互,提升模型表达能力。
在树的每一层采用beam search的方式采样出topK个结点,到了最后一层叶子节点的时候,即可得到topK个商品。
联合训练
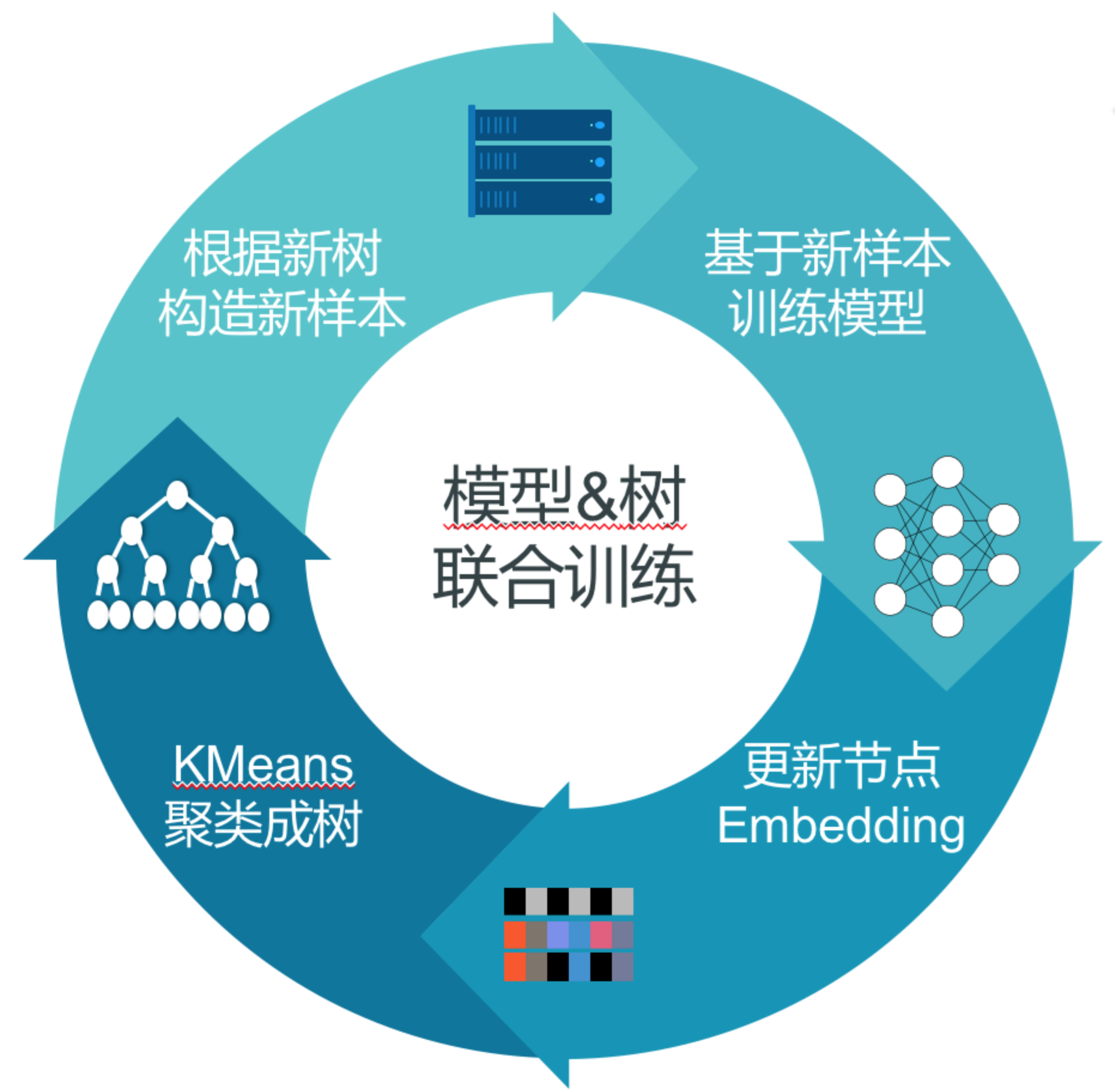
- 初始化二叉树:首先借助商品的类别信息进行排序,将相同类别的商品放到一起,然后递归的将同类别中的商品等量的分到两个子类中,直到集合中只包含一项,即最终的具体商品
- 基于树模型生成样本:如果用户点击了某个item,那么从根节点到该叶子节点上的所有节点(不包含根节点)都是正样本,而在每一层的节点中进行随机负采样
- 训练上图的复杂模型直至收敛
- 基于复杂模型得到所有叶子节点的embedding,迭代地进行k-means聚类。每迭代一次,生成一层中间树节点。需要注意如下如下两点:
- 训练得到的中间节点embedding在聚类过程中是不使用的,只用到叶子节点embedding
- 在线上serving的时候,中间节点embedding会输入到模型中得到topK个结点,每一层下去得到topK个商品
- 重复2~4过程
上述的步骤,至始至终都是在训练一个模型,而不是每一层一个模型(或者每棵树一个模型)