Knowledge Distillation

知识蒸馏是将训练好的大模型包含的知识蒸馏到小模型中。在线上部署的时候,我们使用小模型即可。
蒸馏过程示意图
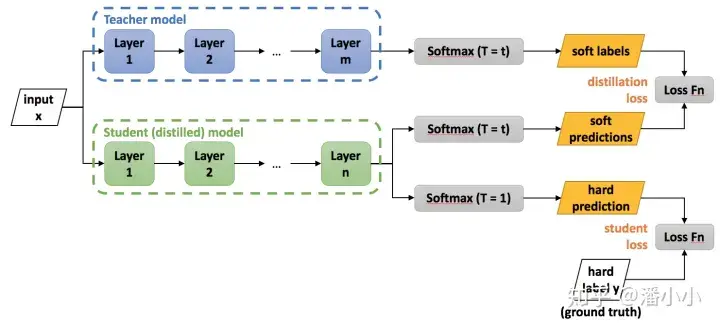
总损失函数
- $L_{\text {soft }}=-\sum_j^N p_j^T \log \left(q_j^T\right)$
- $p_i^T=\frac{\exp \left(v_i / T\right)}{\sum_k^N \exp \left(v_k / T\right)}, q_i^T=\frac{\exp \left(z_i / T\right)}{\sum_k^N \exp \left(z_k / T\right)}$
- $v_i, z_i$ 分别为教师模型和学生模型产生的logits,$N$ 为类别数,$T$ 为温度
- $L_{h a r d}=-\sum_j^N c_j \log \left(q_j^1\right)$
- $q_i^1=\frac{\exp \left(z_i\right)}{\sum_k^N \exp \left(z_k\right)}$
关于温度 $T$
- $T$ 越大,softmax概率分布比原始更平缓,学生模型会更加关注到负标签的信息
- $T$ 越小,softmax概率分布比原始更陡峭,学生模型会更加关注到正标签的信息