
用户序列长度跟模型AUC有直接正相关性,模型能处理的序列长度越长,AUC就越高。但长序列对于样本处理和模型训练非常不友好,耗时长且显存占用大。更重要的是线上预估服务的约束,必须要在规定时间内完成推算。针对长序列的建模,出现了如下代表性工作:
DIN
具体的讲解见:DIN解读
SIM
SIM利用两阶段来捕捉用户在广告上的精准兴趣表达:
- 提出GSU(General Search Unit)结构:从原始的超长用户行为中根据广告信息搜索到和广告相关的用户行为。搜索后的用户行为数据能够由原来的上万长度降低到数百长度,与此同时大部分和当前广告无关的信息都会被过滤。搜索方法有如下两种:
- hard模式:将该用户行为序列中与target item具有相同类别的items聚合起来
- soft模式:用聚类方法将用户行为序列中的items进行聚类
- 提出ESU(Exact Search Unit,精准搜索单元)结构:利用第一阶段提取出和广告相关的用户行为和候选的广告信息来精准建模用户的多样兴趣。在ESU中,采用类似DIN这样复杂的模型来捕捉用户和广告相关的动态兴趣表达
SIM存在的问题
- 目标不一致:GSU建立索引使用的item embedding不是SIM模型生成的,可能是预训练的,也有可能是直接拿item的类别建立的索引,本质上是内容embdding上的索引。但是SIM模型本身的item embdding不一定是这样的内容embdding,要不然就不会有啤酒尿布这样经典的案例(毕竟啤酒和尿布分属不同类别)
- 更新频率不一致:SIM两阶段的更新频率不一致。线上模型都是以online learning的方式频繁更新的,以捕捉用户实时的兴趣变化,但是SIM中所使用的索引都是离线建立好的,成为性能的短板
ETA
模型结构如下: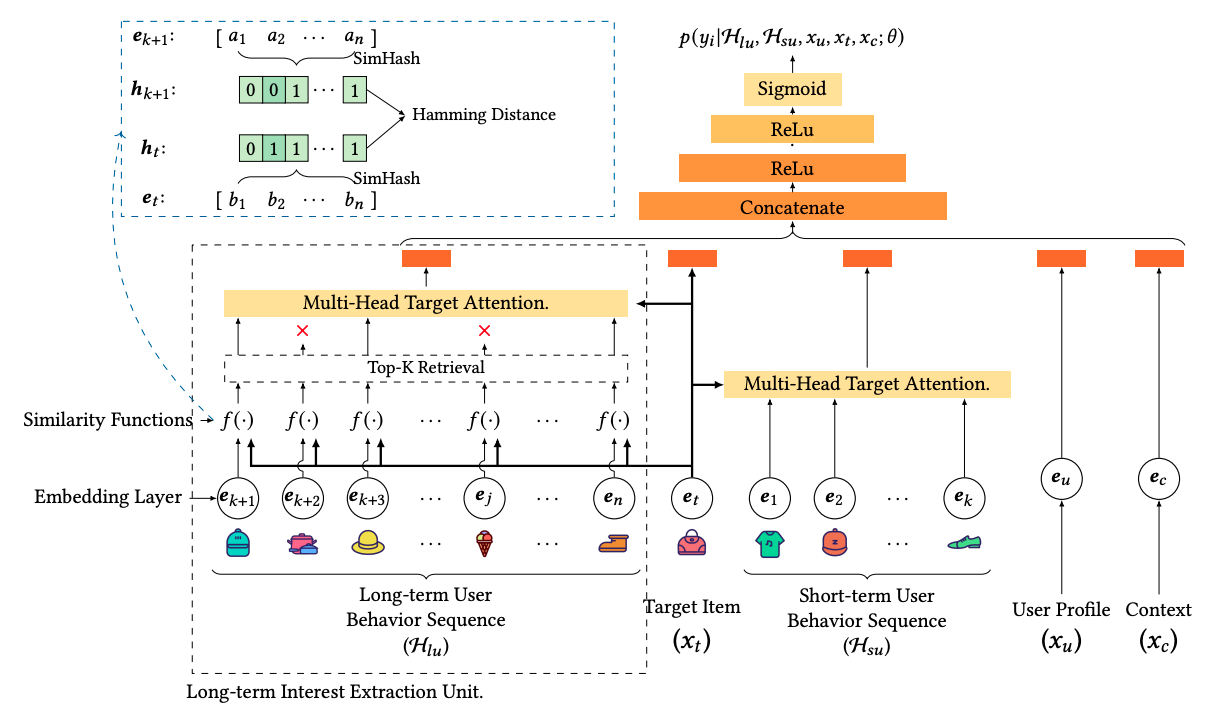
SimHash伪代码如下:
在使用SimHash算法前,Multi-Head Target Attention的复杂度为 $O(B \times L \times d)$,$B$ 为候选集个数(即target item数量),$L$ 为用户长序列长度,$d$ 为item embedding维度。
使用SimHash算法后,候选集的所有item与历史行为序列计算汉明距离的复杂度为 $O(B \times L)$,接着取出TopK相似的历史item,并进行Attention操作,复杂度为 $O(B \times K \times d)$,总体复杂度 $O(B \times L + B \times K \times d) \approx O(B \times K \times d) \ll O(B \times L \times d)$
SDIM
模型结构如下:
通过对用户行为序列中与target item具有相同哈希次序列的item的embedding求和,再归一化后得到用户兴趣表达,将时间复杂度进一步降低到 $O(B \times m \times log(d))$,$m$ 为hash函数个数。
SDIM结构简单,去掉了ETA的TopK检索部分(只取部分,丢失了用户的部分序列信息),也去掉了Multi-Head Attention,直接在原始、完整的序列上建模,效果也更好。
总结
对于长序列建模的思路,主流都是将Attention操作($O(d)$)优化成hash操作($O(1)$)。模型结构上倒不是很复杂,比拼的更多是工程能力、基建能力,比如:
- 模型的超参设置多大合适?
- 千亿商品能建下多大的索引?
- 机器资源能容得下多大并发?
- 不同的场景是否sota模型真的有效?