
FM 是搜广推里最经典的算法,这里记录一下原理与公式推导:
FM
参数数量和时间复杂度优化
当我们使用一阶原始特征和二阶组合特征来刻画样本的时候,会得到如下式子:
$x_i$ 和 $x_j$ 分别表示两个不同的特征取值,对于 $n$ 维的特征来说,这样的二阶组合特征一共有 $\frac{n(n-1)}{2}$ 种,也就意味着我们需要同样数量的权重参数。但是由于现实场景中的特征是高维稀疏的,导致 $n$ 非常大,比如上百万,这里两两特征组合的特征量级 $C_n^2$ ,所带来的参数量就是一个天文数字。对于一个上百亿甚至更多参数空间的模型来说,我们需要海量训练样本才可以保证完全收敛。这是非常困难的。
FM解决这个问题的方法非常简单,它不再是简单地为交叉之后的特征对设置参数,而是设置了一种计算特征参数的方法。
FM模型引入了新的矩阵 $V$ ,它是一个 $n \times k$ 的二维矩阵。这里的 $k$ 是超参,一般不会很大,比如16、32之类。对于特征每一个维度 $x_i$ ,我们都可以找到一个表示向量 $v_i \in R^k$ 。从NLP的角度来说,就是为每个特征学习一个embedding。原先的参数量从 $O(n^2)$ 降低到了 $O(k \times n)$ 。ALBERT论文的因式分解思想跟这个非常相似:$O(V \times H) \ggg O(V \times E + E \times H)$
有了 $V$ 矩阵,上式就可以改写成如下形式:
当 $k$ 足够大的时候,即 $k = n$ ,那么就有 $W = V$ 。在实际的应用场景当中,我们并不需要设置非常大的K,因为特征矩阵往往非常稀疏,我们可能没有足够多的样本来训练这么大量的参数,并且限制K也可以一定程度上提升FM模型的泛化能力。
此外这样做还有一个好处就是有利于模型训练,因为对于有些稀疏的特征组合来说,我们所有的样本当中可能都是空的。比如在刚才的例子当中用户A和电影B的组合,可能用户A在电影B上就没有过任何行为,那么这个数据就是空的,我们也不可能训练出任何参数来。但是引入了 $V$ 之后,虽然这两项缺失,但是我们针对用户A和电影B分别训练出了向量参数,我们用这两个向量参数点乘,就得到了这个交叉特征的系数。
虽然我们将模型的参数降低到了 $O(k \times n)$ ,但预测一条样本所需要的时间复杂度仍为 $O(k \times n^2)$ ,这仍然是不可接受的。所以对它进行优化也是必须的,并且这里的优化非常简单,可以直接通过数学公式的变形推导得到:
FM模型预测的时间复杂度优化到了 $O(k \times n)$ .
模型训练
优化过后的式子如下:
针对FM模型我们一样可以使用梯度下降算法来进行优化。既然要使用梯度下降,那么我们就需要写出模型当中所有参数的偏导,主要分为三个部分:
- $w_0$ : $\frac{\partial \theta}{\partial w_{0}}=1$
- $\sum_{i=1}^{n} w_{i} x_{i}$ : $\frac{\partial 0}{\partial w_{i}}=x_{i}$
- $\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)$ : $\frac{\partial \hat{y}}{\partial v_{i, f}} = \frac{1}{2} (2x_i (\sum_{j=1}^{n} v_{j, f} x_{j}) - 2v_{i,f} x_i^2) = x_{i} \sum_{j=1}^{n} v_{j, f} x_{j}-v_{i, f} x_{i}^{2}$
综合如下:
由于 $\sum_{j=1}^n v_{j,f} x_j$ 是可以提前计算好存储起来的,因此我们对所有参数的梯度计算也都能在 $O(1)$ 时间复杂度内完成。
拓展到 $d$ 维
参照刚才的公式,可以写出FM模型推广到d维的方程:
以 $d=3$ 为例,上式为:
它的复杂度是 $O(k \times n^d)$ 。当 $d=2$ 的时候,我们通过一系列变形将它的复杂度优化到了 $O(k \times n)$ 。而当 $d > 2$ 的时候,没有很好的优化方法,而且三重特征的交叉往往没有意义,并且会过于稀疏,所以我们一般情况下只会使用 $d=2$ 的情况。
最佳实践
1 | import torch |
DeepFM
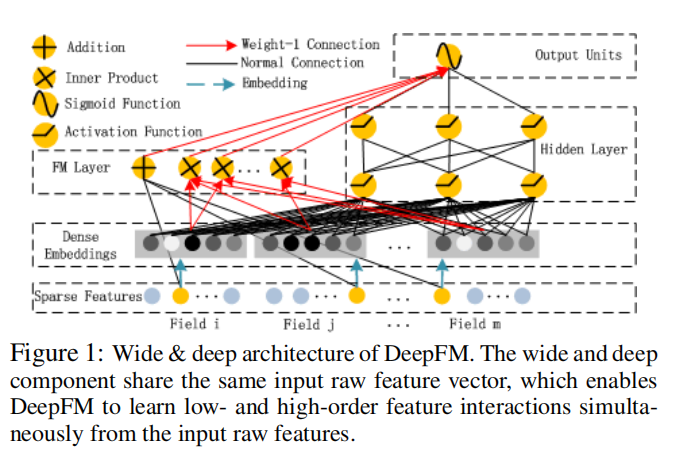
FM
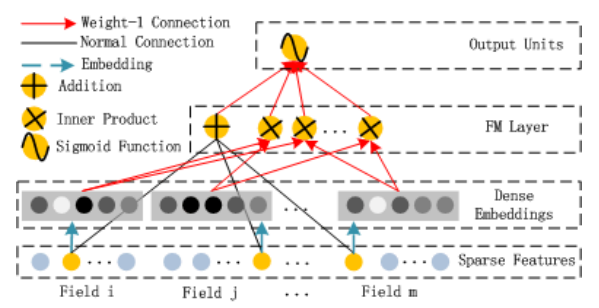
该组件就是在计算FM:
注意不是:$w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right)$
- 每个 $Field$ 是one-hot形式,黄色的圆表示 $1$ ,蓝色的代表 $0$
- 连接黄色圆的黑线就是在做:$\langle w, x\rangle$
- 连接embedding的红色线就是在做:$\sum_{j_{1}=1}^{d} \sum_{j_{2}=j_{1}+1}^{d}\left\langle V_{i}, V_{j}\right\rangle x_{j_{1}} \cdot x_{j_{2}}$
DNN
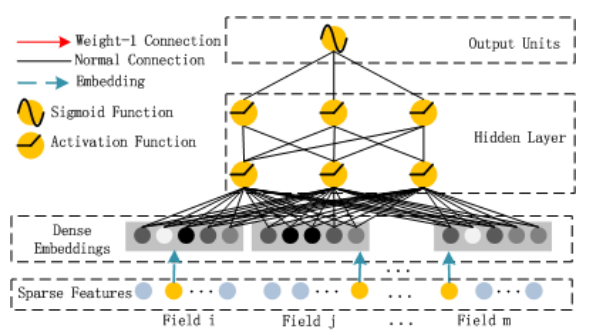
DNN部分比较简单,但它是与FM部分共享Embedding的。