分布式训练

在面试中,遇到有些面试官会问分布式训练的有关问题,在此总结一下。
分布式训练的并行方式主要分如下两种:
- 数据并行:将数据集切分放到各计算节点,每个计算节点的计算内容完全一致,并在多个计算节点之间传递模型参数。数据并行可以解决数据集过大无法在单机高效率训练的问题,也是工业生产中最常用的并行方法。
- 模型并行:通常指将模型单个算子计算分治到多个硬件设备上并发计算,以达到计算单个算子计算速度的目的。一般会将单个算子的计算,利用模型并行的方式分配在配置相同的几个硬件上,进行模型存储和计算,以保证计算步调一致。
这里详细介绍数据并行的两种训练架构:
- Parameter Server:该架构可以对模型参数的存储进行分布式保存,因此对于存储超大规模模型参数的训练场景十分友好。因此在个性化推荐场景中(任务需要保存海量稀疏特征对应的模型参数)应用广泛。
- Collective:多被用于视觉、自然语言处理等需要复杂网络计算(计算密集型)的模型训练任务场景。
Parameter Server
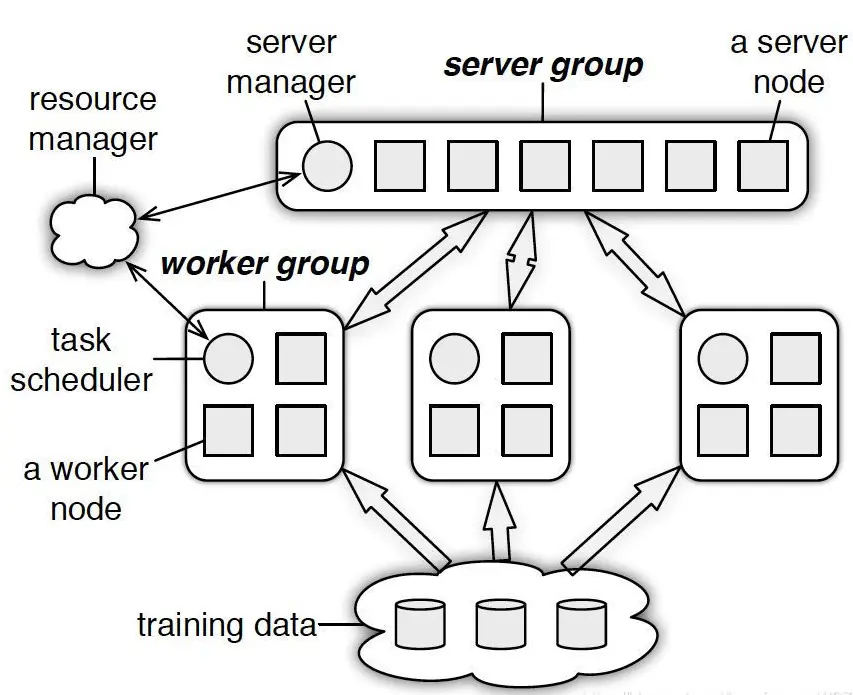
PS分为两大部分:server group和多个worker group,另外resource manager负责总体的资源分配调度。
- server group内部包含多个server node,每个server node负责维护一部分参数,server manager负责维护和分配server资源;
- 每个worker group对应一个application(即一个模型训练任务),worker group之间以及worker group内部的worker node互相之间并不通信,worker node只与server通信。
具体的架构详解可见:一文读懂「Parameter Server」的分布式机器学习训练原理
总结一下Parameter Server实现分布式机器学习模型训练的要点:
- 用异步非阻断式的分布式梯度下降策略替代同步阻断式的梯度下降策略;
- 实现多server节点的架构,避免了单master节点带来的带宽瓶颈和内存瓶颈;
- 使用一致性哈希,range pull和range push等工程手段实现信息的最小传递,避免广播操作带来的全局性网络阻塞和带宽浪费。
Collective
主要有 TreeAllReduce 和 RingAllReduce 两种。
TreeAllReduce
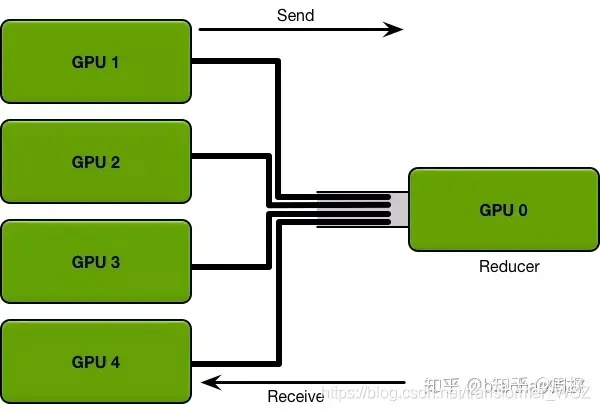
该架构已被抛弃,存在如下两个问题:
- 每一轮的训练迭代都需要所有卡都将数据同步完做一次Reduce才算结束。如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
- 每次迭代所有的GPU卡都需要针对全部的模型参数跟Reduce卡进行通信,如果参数的数据量大的时候,那么这种通信开销也是非常庞大,而且这种开销会随着卡数的增加而线性增长。
RingAllReduce
与 TreeAllReduce 不同, RingAllreduce 算法的每次通信成本是恒定的,与系统中GPU的数量无关,完全由系统中gpu之间最慢的连接决定。
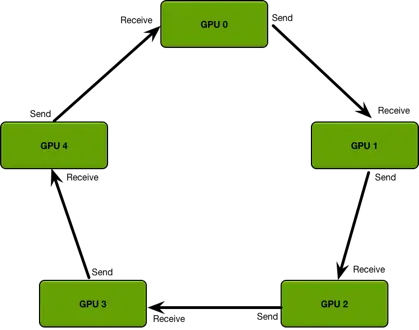
RingAllReduce 中的GPU排列在一个逻辑环中。 每个GPU应该有一个左邻居和一个右邻居。它只会向其右邻居发送数据,并从其左邻居接收数据。
该算法分两步进行:
- scatter-reduce:GPU交换数据,使得每个GPU最终得到最终结果的一部分;
- all-gather:GPU交换这些块,以便所有GPU最终得到完整的最终结果。
具体示例可见:分布式训练-Ring AllReduce