
关于GBDT的算法原理和实例讲解可见:
下面是涉及到的GBDT的面试问答:
基本原理
通过多轮迭代,每轮迭代产生一个弱分类器(利用CART回归树构建),每个分类器在上一轮分类器的残差基础上进行训练。最后将这些弱分类器线性组合成一个强学习器。
GBDT如何做特征选择?
- 遍历样本的特征,对于每个特征,遍历样本的切分点,选择最优的特征的最优切分点;
- 判断最优时使用平方误差。使用一个特征及其切分点可将样本分为两部分,每部分都计算一个标签的平均值,计算标签平均值与标签的平方误差之和,平方误差最小的特征–切分点组合即是最优的。
GBDT如何构建特征?
gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。
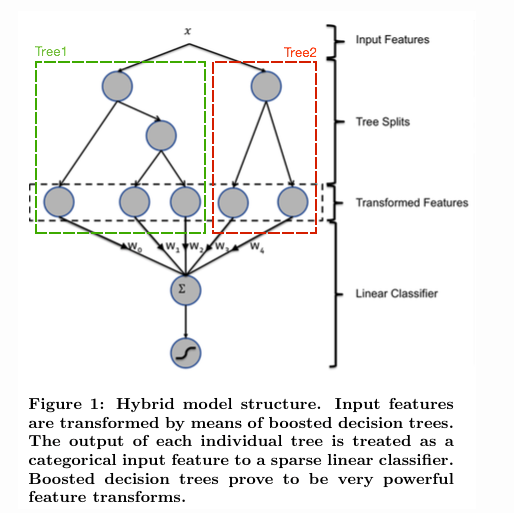
如上图所示,使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为0。
于是对于该样本,我们可以得到一个向量 $[0,1,0,1,0]$ 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。
GBDT如何用于分类?
GBDT无论用于分类还是回归一直都是使用的CART 回归树。因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 $x$ 属于A类,本一轮训练输出的是样本 $x$ 属于B类。 A 和 B 很多时候甚至都没有比较的意义,A类-B类是没有意义的。
具体到多分类这个任务上来,假设样本 $X$ 总共有 $K$ 类。来了一个样本 $x$ ,我们需要使用GBDT来判断 $x$ 属于样本的哪一类。
第一步 我们在训练的时候,是针对样本 $X$ 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 $K = 3$ 。样本 $x$ 属于第二类。那么针对该样本 $x$ 的分类结果,其实我们可以用一个 三维向量 $[0,1,0]$ 来表示。 $0$ 表示样本不属于该类, $1$ 表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为 $1$,其他位置为 $0$ 。
针对样本有三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为 $(x,0)$ 。第二颗树输入针对样本x的第二类,输入为 $(x,1)$ 。第三颗树针对样本x的第三类,输入为 $(x,0)$
在这里每颗树的训练过程其实就是我们之前已经提到过的CATR TREE 的生成过程。在此处我们参照之前的生成树的程序 即可以就解出三颗树,以及三颗树对 $x$ 类别的预测值 $f_1(x),f_2(x),f_3(x)$ 。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax来产生概率,则属于类别 $1$ 的概率:
并且我们我们可以针对类别1求出残差$y_1 = 0-p_1(x)$;类别2 求出残差$y_2 = 1-p_2(x)$;类别3 求出残差$y_3 = 0-p_3(x)$
然后开始第二轮训练 针对第一类 输入为$(x, y_1(x))$, 针对第二类输入为$(x, y_2(x))$,针对 第三类输入为$(x, y_3(x))$。继续训练出三颗树。一直迭代M轮,每轮构建3颗树。
所以当 $K=3$ ,我们其实应该有三个式子:
当训练完毕以后,新来一个样本x,我们需要预测该样本的类别的时候,便可以有这三个式子产生三个值$F_{1M}(x),F_{2M}(x),F_{3M}(x)$。样本属于 某个类别c的概率为:
GBDT通过什么方式减少误差?
每棵树都是在拟合当前模型的预测值和真实值之间的误差,GBDT是通过不断迭代来使得误差减小的过程。
GBDT的效果相比于传统的LR,SVM效果为什么好一些 ?
GBDT基于树模型,继承了树模型的优点(对异常点鲁棒(使用了Huber损失函数和Quantile损失函数)、不相关的特征干扰性低(LR需要加正则)、可以很好地处理缺失值、受噪音的干扰小)
注:相对于RF,GBDT对异常值比较敏感,原因是当前的错误会延续给下一棵树。
RF和GBDT的异同
- 相同点:都是由多棵树组成,最终结果由多棵树一起决定。
- 不同点:
- 集成学习:RF属于bagging思想,而GBDT是boosting思想
- 偏差-方差权衡:RF不断的降低模型的方差,而GBDT不断的降低模型的偏差
- 训练样本:RF每次迭代的样本是从全部训练集中有放回抽样形成的,而GBDT每次使用全部样本
- 并行性:RF的树可以并行生成,而GBDT只能顺序生成(需要等上一棵树完全生成)
- 最终结果:RF最终是多棵树进行多数表决(回归问题是取平均),而GBDT是加权融合
- 数据敏感性:RF对异常值不敏感,而GBDT对异常值比较敏感
- 泛化能力:RF不易过拟合,而GBDT容易过拟合
比较LR和GBDT,说说什么情景下GBDT不如LR?
- LR是线性模型,可解释性强,很容易并行化,但学习能力有限,需要大量的人工特征工程。
- GBDT是非线性模型,具有天然的特征组合优势,特征表达能力强,但是树与树之间无法并行训练,而且树模型很容易过拟合。
当在高维稀疏特征的场景下,LR的效果一般会比GBDT好。具体示例见:12. 比较LR和GBDT,说说什么情景下GBDT不如LR
GBDT的参数有哪些,如何调参 ?
- 学习率
- 最大弱学习器的个数(太小欠拟合,太大过拟合 )
- 子采样(防止过拟合,太小欠拟合。GBDT中是不放回采样 )
- 最大特征数
- 最大树深(太大过拟合)
- 内部节点再划分所需最小样本数(越大越防过拟合 )
- 叶子节点最小的样本权重和(如果存在较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重。越大越防过拟合)
- 最大叶子节点数(太大过拟合)
GBDT的优缺点?
优点:
可以灵活处理各种类型的数据,包括连续值和离散值。
在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
使用一些健壮的损失函数,对异常值的鲁棒性非常强
缺点:由于弱学习器之间存在依赖关系,难以并行训练数据。
GBDT的“梯度提升”体现在哪个阶段?
在构建CART树时使用了损失函数的负梯度,而不是所谓的残差=真值-预测值;实际上是一种更宽广的概念,但是在平方损失的情况下,上面等式是成立的。另外使用损失函数的梯度可以保证损失函数最小值。所以GBDT的梯度提升体现在构建CART树的所需的负梯度阶段,其利用最速下降的近似方法。
怎样设置单棵树的停止生长条件?
- 最大深度
- 最多叶子结点数
- 结点分裂时的最小样本数
- loss满足约束条件
GBDT哪些部分可以并行?
- 计算并更新每个样本的负梯度;
- 分裂挑选最佳特征及其分割点时,对特征计算相应的误差及均值时;
- 最后预测过程中,每个样本将之前的所有树的结果累加的时候。