BERT、RoBerta、XLNet、ALBERT对比

记录一下BERT变体的比较。
BERT
BERT堆叠了多层Transformer的Encoder模块,设计了两个任务来完成预训练:
- Masked LM:随机mask掉15%的token,其中80%替换为[MASK],10%替换为其它token,10%保留原单词。
- Next Sentence Prediction(NSP):从训练集中抽取A和B句,50%为A的下一句,50%为其它句子。
RoBerta
静态Mask VS 动态Mask
- 静态Mask:BERT对每一个序列随机选择15%的tokens替换成[MASK],而一旦被选中,之后的N个epoch就不能再改变。
- 动态Mask:RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Mask,也就是说,同样的一句话有10种不同的mask方式。然后每份数据都训练N/10个epoch。
NSP VS w/o NSP
RoBerta去除了NSP任务,每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES),而原来的Bert每次只输入两个句子。
hyper-parameter
- 更大的batch_size
- 更多的数据
- 更高的学习率
- 更长时间的训练
XLNet
AR LM:利用上下文单词预测下一个单词的一种模型。但是在这里,上下文单词被限制在两个方向,要么向前,要么向后。
AE LM:从损坏的输入中重建原始数据的一种模型。它可以同时在向前向后两个方向看到上下文。
BERT存在的问题:
- 掩码导致的微调差异:预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失。
- 预测的标记彼此独立:Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系。
XLNet在输入侧维持表面的X句子单词顺序,在Transformer内部,看到的已经是被重新排列组合后的顺序,是通过Attention Mask来实现的。从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,放到Ti的上文位置中,把其它单词的输入通过Attention Mask隐藏掉,于是就能够达成我们期望的目标。
双流自注意力机制
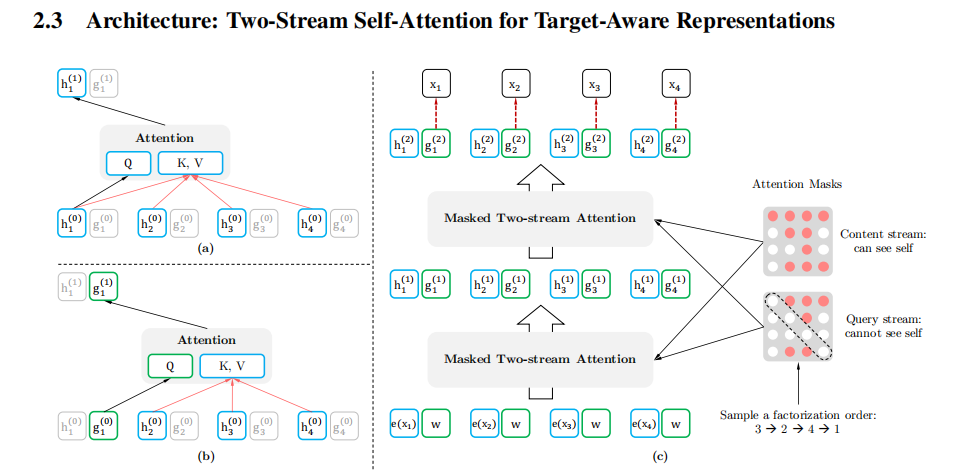
- content stream self-attention $h_{\theta}\left(\mathbf{x}_{\mathbf{z}_{\leq t}}\right)$:标准的Transformer计算,能同时接触到单词x的特征信息和位置信息。
- query stream self-attention $g_{\theta}\left(\mathbf{x}_{\mathbf{z}_{<t}}, z_{t}\right)$:只能接触到单词x的位置信息。
计算过程如下:
其它改进措施:
- 引入Transformer-XL:相对位置编码以及分段RNN机制。解决Transformer对长文档应用不友好的问题。
- 使用更多更高质量的数据。
ALBert
词嵌入向量参数的因式分解(Factorized embedding parameterization)
在BERT、XLNet中,词表的embedding size(E)和transformer层的hidden size(H)是等同的,所以E=H。但实际上词库的大小一般都很大,这就导致模型参数个数就会变得很大。为了解决这些问题他们提出了一个基于factorization的方法。
跨层参数共享(Cross-layer parameter sharing)
每一层的Transformer可以共享参数,这样一来参数的个数不会以层数的增加而增加。
段落连续性任务(Inter-sentence coherence loss)
后续的研究表示NSP过于简单,性能不可靠。使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。