Swift's Blog
HOME
ARCHIVES
TAGS
CATEGORIES
LINKS
ABOUT
HOME
ARCHIVES
TAGS
CATEGORIES
LINKS
ABOUT
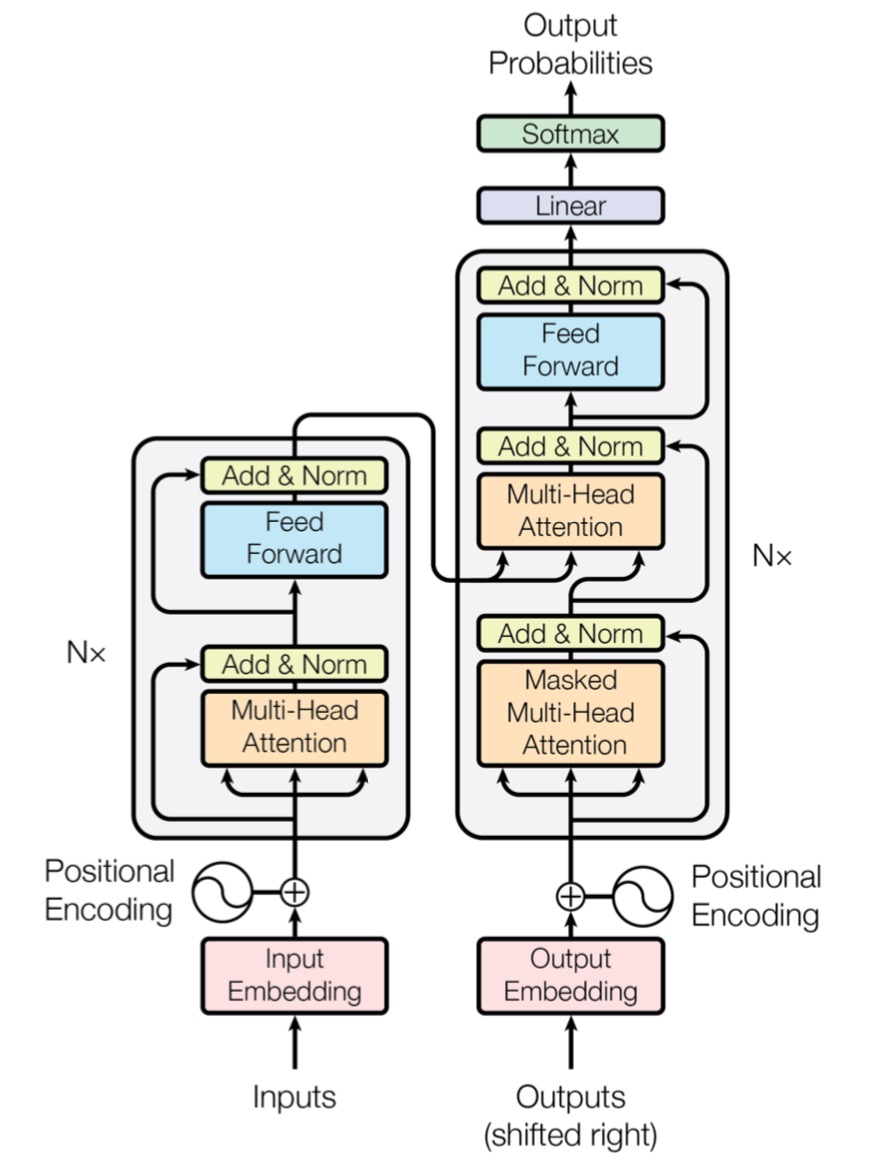
Transformer
Swift
Lv6
2019-07-25 09:04:33
2019-07-25 09:04:33
NLP
Paper Reading
Attention
Encoder-Decoder
要点如下:
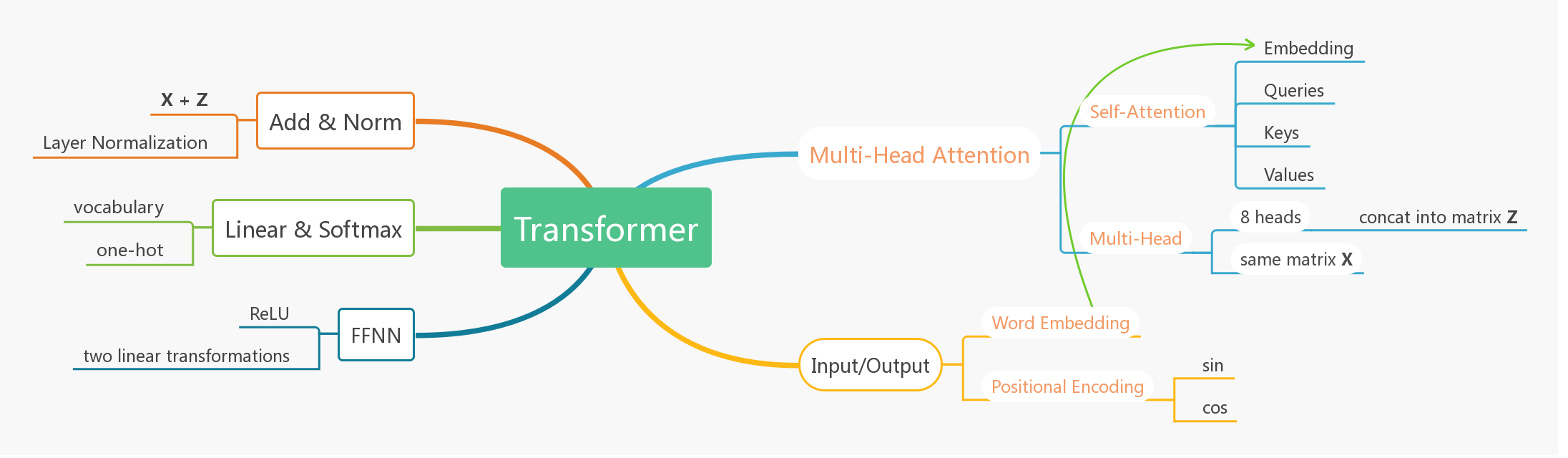
Notes
Self-Attention
:表示自注意。在机器翻译中,attention分配通常是目标单词对源语句各单词的概率分布。而self-attention表示source —> source的attention分配,这样每个单词便能捕获与其他所有单词的关系特征,解决了RNN无法学习长程特征的问题。
Multi-Head
:表示 $X$ 同时做多次映射得到多个query、key、value。
参考
Attention Is All You Need
The Illustrated Transformer
Paper Reading
Attention
Encoder-Decoder
Dataset
Prev posts
Attention Model
Next posts
1.
Notes
2.
参考
1.
Notes
2.
参考