
卷积神经网络(Convolutional Neural Networks)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。CNN在图像分类数据集上有非常突出的表现。
DNN与CNN
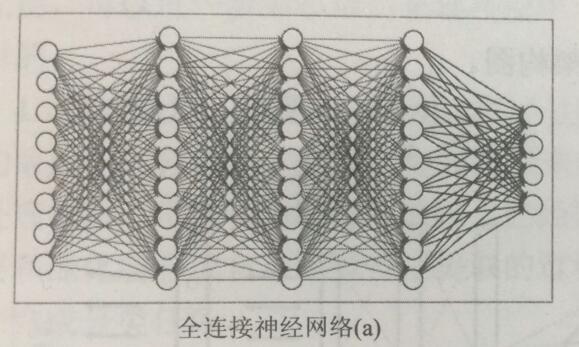
下图为DNN:
下图为CNN:
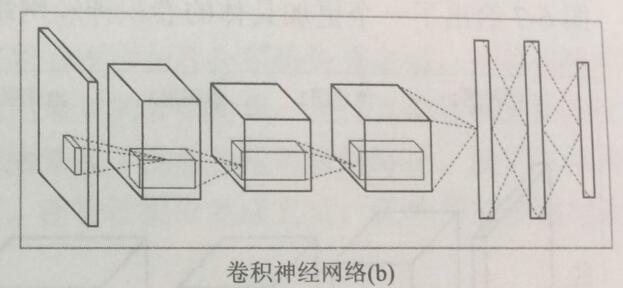
虽然两张图的结构直观上差异较大,但实际上它们的整体架构是非常相似的。
- CNN通过一层一层的节点组织起来。
- 和DNN一样,CNN的每一个节点都是一个神经元。
- CNN的输入输出与DNN基本一致。以图像分类为例,CNN的输入层就是图像的原始像素,而输出层中的每一个节点代表了不同类别的可信度。DNN中的损失函数以及参数的优化过程也适用于CNN。
CNN结构
使用DNN处理图像的最大问题在于全连接层的参数太多。对于MNIST数据,每一张图片的大小为28*28*1,1表示图像是黑白的,只有一个彩色通道。假设第一层隐藏层的节点数为500个,那么一个全连接层的神经网络会有28*28*500+500=392500个参数。如果图片采取更大的规格,比如有RGB三个彩色通道,那么参数数量更是巨大。过多的参数会导致计算速度减慢以及过拟合。而CNN可以有效的减少参数的个数。下图是具体的CNN结构图:
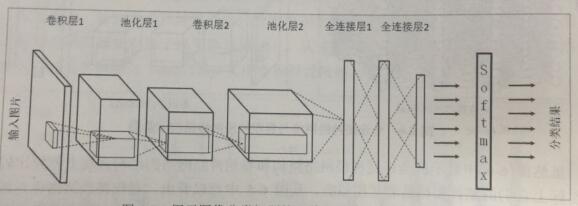
在CNN的前几层中,每一层的节点都被组织成一个三维矩阵。比如将输入的图片组织成一个32*32*3的三维矩阵。从上图中可以看出CNN的前几层中每个节点只和上一层中部分的节点相连。CNN主要由以下5中结构组成:
输入层
输入层是整个神经网络的输入,在处理图像的CNN中,它一般代表了一张图片的像素矩阵。在上图的最左侧的三维矩阵就可以代表一张图片。三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。
卷积层(Convolution Layer)
卷积层是CNN最重要的部分。和传统全连接层不同,卷积层中每一个节点的输入只是上一层神经网络的一小块。下图为卷积层的过滤器(filter)或者内核(kernel):
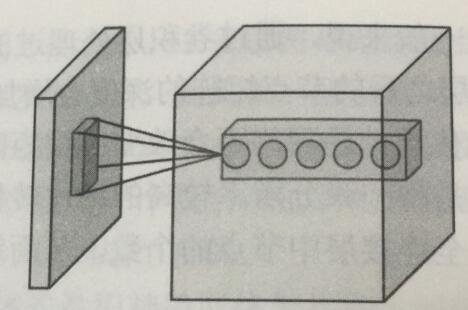
filter可以将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵(长宽均为1,但深度不限)。filter的尺寸指的是filter输入节点矩阵的大小,通常有3*3或5*5。filter处理的矩阵深度和当前层神经网络节点矩阵(输入节点矩阵)的深度是一致的,而filter的深度指的是输出单位节点的深度。
示例
下图展示了如何通过filter将一个2*2*3的节点矩阵转化为一个1*1*5的单位节点矩阵。

一个filter的前向传播过程和全连接层相似,它总共需要2*2*3*5+5个参数,+5表示偏置项参数的个数。假设使用$w_{x,y,z}^i$ 表示对于输出单位节点矩阵中的第i个节点,filter输入节点 $(x, y, z)$ 的权重,使用 $b^i$ 表示第i个输出节点对应的偏置项参数,那么单位矩阵中的第i个节点的取值 $g(i)$ 为:
其中 $a_{x, y, z}$ 为filter节点 $(x, y, z)$ 的取值,$f$ 采用ReLU作为激活函数。上图展示了 $g(0)$ 的计算过程。每一个二维矩阵表示三维矩阵在某一个深度上的取值。
卷积层结构的前向传播就是通过将一个filter从神经网络当前层的左上角移动到右下角(即滑过整个图像),并在移动过程中重复上述运算:

调整输出矩阵大小
全0填充
为了避免卷积层前向传播过程中节点矩阵的尺寸的变化,可以在当前矩阵的边界上加入全0填充。这样可以使得卷积层前向传播结果矩阵的大小和当前层矩阵保持一致:
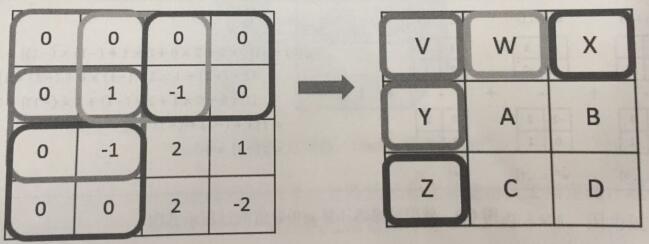
步长
下图显示了filter步长为2且使用全0填充时,卷积层前向传播的过程:
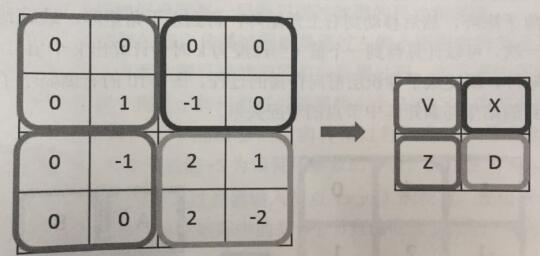
输出矩阵的大小
宽度:
高度:
深度有人工指定。
- $W$:输入图像的宽度
- $H$:输入图像的高度
- $F_w$:filter的宽度
- $F_h$:filter的高度
- $P$:全0填充的宽度
- $S$:移动步幅
参数共享
当前卷积层中所有过滤器的参数是共享的,这样就可以巨幅减少神经网络上的参数。假设输入层矩阵的的维度为32*32*3,第一层卷积层filter尺寸为5*5,深度为16,那么这个卷积层的参数个数为5*5*3*16+16=1216个。如果使用全连接层,那么全连接层的参数个数为32*32*3*500=1536000个。相比之下,卷积层的参数个数要远远小于全连接层。卷积层的参数个数与图片的大小无关,它只和filter的尺寸、深度以及当前输入层的深度有关。这使得CNN可以很好地扩展到更大的图像数据上。
池化层(Pooling Layer)
池化层不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络参数的目的。使用池化层既可以加快计算速度也可以防止过拟合。
池化层filter的计算不是节点的加权和,而是采用最大值或者平均值计算。使用最大值操作的池化层被称之为最大池化层(max pooling),这是被使用得最多的池化层结构。使用平均值操作的池化层被称之为平均池化层(average pooling)。
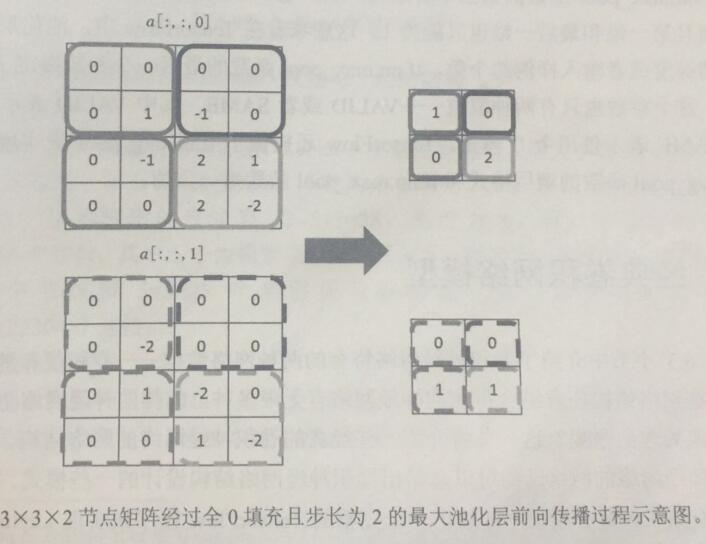
池化层前向传播的过程也是通过移动一个类似filter的结构完成的。与卷积层的filter类似,池化层的filter也需要人工设定filter的尺寸、全0填充以及filter的步长。卷积层和池化层的filter移动方式也是相似的,唯一的区别在卷积层使用的filter是横跨整个深度的,而池化层使用的filter只影响一个深度上的节点。所以池化层的filter除了在长和宽两个维度移动外,它还需要在深度这个维度移动。如下图所示:
全连接层
在经过多轮卷积层和池化层的处理之后,在CNN的最后一般会由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在提取完成之后,仍然需要使用全连接层来完成分类任务。
Softmax层
通过Softmax层,可以得到当前样例属于不同种类的概率分布问题。